XuanCe: A Comprehensive and Unified Deep Reinforcement Learning Library¶






XuanCe is an open-source ensemble of Deep Reinforcement Learning (DRL) algorithm implementations. The name “XuanCe” (玄策) comes from two Chinese characters:
“Xuan” (玄) means incredible, mysterious, or profound.
“Ce” (策) means policy or strategy.
Together, XuanCe represents “incredible policies”, reflecting the goal of discovering optimal policies through DRL.
DRL algorithms are sensitive to hyper-parameters tuning, varying in performance with different tricks, and suffering from unstable training processes, therefore, sometimes DRL algorithms seems elusive and “Xuan”. That is why this project exists: to provide clean, easy-to-understand implementations of DRL algorithms. We hope it can help uncover some of the “magic” behind DRL and make it a bit less mysterious.
We are also working to make XuanCe compatible with popular deep learning frameworks like
PyTorch (  ), TensorFlow (
), TensorFlow (  ), and MindSpore (
), and MindSpore (  ).
Our goal is to turn it into a full-fledged DRL “zoo” where you can explore and experiment with a wide variety of algorithms.
).
Our goal is to turn it into a full-fledged DRL “zoo” where you can explore and experiment with a wide variety of algorithms.
Why XuanCe?¶
XuanCe is designed to streamline the implementation and development of deep reinforcement learning algorithms. It empowers researchers to quickly grasp fundamental principles, making it easier to dive into algorithm design and development. Here are its key features:
Highly Modular: Designed with a modular structure to enhance flexibility and scalability.
User-Friendly: Easy to learn, install, and use, making it accessible for users of all levels.
Flexible Model Integration: Supports seamless combination and customization of models.
Diverse Algorithms: Offers a rich collection of algorithms catering to various tasks.
Versatile Task Support: Handles both deep reinforcement learning (DRL) and multi-agent reinforcement learning (MARL) scenarios.
Broad Compatibility: Supports PyTorch, TensorFlow, MindSpore, and runs efficiently on CPU, GPU, and across Linux, Windows, and macOS.
High Performance: Delivers fast execution speeds, leveraging vectorized environments for efficiency.
Distributed Training: Enables multi-GPU training for scaling up experiments.
Hyperparameters Tuning: Supports automatically hyperparameters tuning.
Enhanced Visualization: Provides intuitive and comprehensive visualization with tools like TensorBoard and Weights & Biases (wandb).
List of Algorithms¶
flowchart LR
CORE["Unified Framework (Modularized) <br/>Representation + Policy + Communication (for MARL) + Learner + Agent"]
CORE --> Value[Value-based]
CORE --> Policy[Policy-based]
CORE --> MARL[MARL]
CORE --> Model[Model-based]
CORE --> Contrastive[Contrastive RL]
CORE --> Offline[Offline RL]
Value --> DQN[DQN/DDQN/DuelDQN...]
Policy --> ON[On-policy: PG/A2C/PPO...]
Policy --> OFF[Off-policy: DDPG/SAC/TD3...]
MARL --> ONMA[On-policy: VDAC/COMA/IPPO/MAPPO...]
MARL --> OFFMA[Off-policy: VDN/QMIX/MADDPG/MASAC...]
MARL --> COMMMA[Communication: CommNet/IC3Net/TarMAC...]
Model --> MBRL[DreamerV2/DreamerV3/HarmonyDreamer...]
Contrastive --> CRL[CURL/DrQ/SPR...]
Offline --> OFFLINERL[TD3BC...]
Value-based:
DQN: Deep Q-Network (DQN).DuelDQN: Dueling Deep Q-Network (Dueling DQN).NoisyDQN: DQN with Noisy Layers (Noisy DQN).DRQN: Deep Recurrent Q-Network (DRQN).C51: Categorical 51 DQN (C51).
Policy-based:
PG: Policy Gradient (PG).PPG: Phasic Policy Gradient (PPG).A2C: Advantage Actor Critic (A2C).SAC: Soft Actor-Critic (SAC).PPO: Proximal Policy Optimization with Clipped Objective (PPO-Clip).PPOKL: Proximal Policy Optimization with KL Divergence (PPO-KL).TD3: Twin Delayed Deep Deterministic Policy Gradient (TD3).
MARL-based:
IQL: Independent Q-Learning (IQL).QMIX: Q-Mixing Networks (QMIX).WQMIX: Weighted Q-Mixing Networks (WQMIX).QTRAN: Q-Transformation (QTRAN).IDDPG: Independent Deep Deterministic Policy Gradient (IDDPG).MADDPG: Multi-agent Deep Deterministic Policy Gradient (MADDPG).MFQ: Mean-Field Q-Learning (MFQ).MFAC: Mean-Field Actor-Critic (MFAC).MATD3: Multi-agent Twin Delayed Deep Deterministic Policy Gradient (MATD3).IC3Net: Individual Controlled Continuous Communication Model (IC3Net).
Model-based:
DreamerV2: Dreamer V2.DreamerV3: Dreamer V3.HarmonyDreamer: HarmonyDreamer.
Contrastive RL:
CURL: Contrastive Unsupervised Representations for Reinforcement Learning (CURL).SPR: Self-Predictive Representations for Reinforcement Learning (SPR).
Offline RL:
The Framework of XuanCe¶
The overall framework of XuanCe is shown as below.
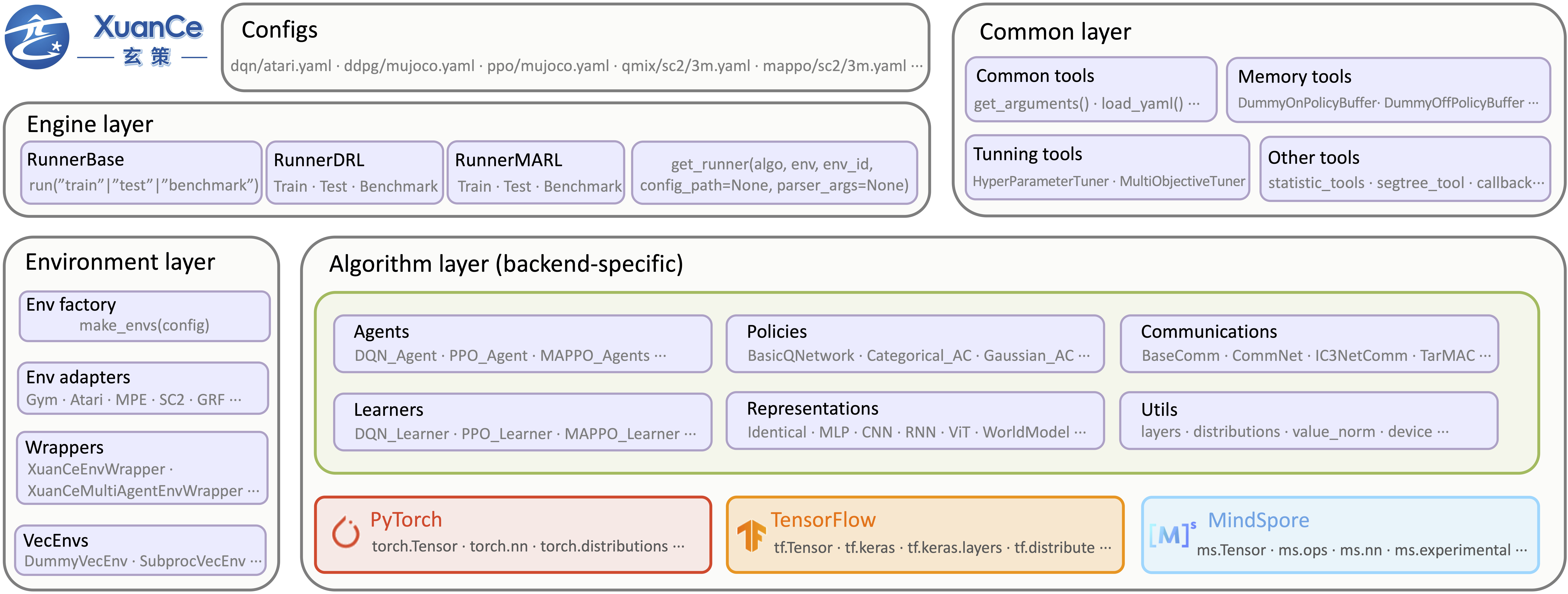
XuanCe contains four main parts:
Part I: Configs. The configurations of hyper-parameters, environments, models, etc.
Part II: Common tools. Reusable tools that are independent of the choice of DL backend.
Part III: Environments. The supported simulated environments.
Part IV: Algorithms. The key part to build DRL algorithms.
Who Is XuanCe For?¶
XuanCe is designed for a wide range of users, including:
Researchers exploring new reinforcement learning methods
Developers building DRL-based applications
Students and beginners learning about intelligent decision-making
AI practitioners interested in single-agent and multi-agent systems
Contents¶
Tutorial:
Benchmarks:
APIs:
Development:
- Github
- Release Log
- XuanCe (1.4.3)
- XuanCe (1.4.2)
- XuanCe (1.4.1)
- XuanCe (1.4.0)
- XuanCe (1.3.3)
- XuanCe (1.3.2)
- XuanCe (1.3.1)
- XuanCe (1.3.0)
- XuanCe (1.2.6)
- XuanCe (1.2.5)
- XuanCe (1.2.4)
- XuanCe (1.2.3)
- XuanCe (1.2.2)
- XuanCe (1.2.1)
- XuanCe (1.2.0)
- XuanCe (1.1.1)
- XuanCe (1.0.11)
- XuanCe (1.0.10)
- XuanCe (1.0.6)
- XuanCe (1.0.1)
- XuanCe (1.0.0)
- Contribute to XuanCe
- Contribute to Docs (EN)
- Contribute to Docs (CN)